Scaling Serverless Beyond the First Function
Real lessons from building and scaling serverless systems, beyond the docs and hype.

When serverless first hit the scene, it sounded almost too good to be true. No servers to provision. No patching, scaling, or load balancing to worry about. Just write your function, deploy it, and let the cloud handle the rest. It promised developer productivity, fewer ops, faster iteration, automatic scaling, and you only pay when your code runs.
At Jodo we jumped in with Lambda, API Gateway, EventBridge, and SQS. From generating payment links to processing webhooks and audit logs, we built with enthusiasm. The tooling felt modern, deployment was simple, and infrastructure melted into the background—exactly what every engineering team dreams of.
But then came 2PM on a weekday.
Everything had been humming along fine. The team was heads-down on feature work when suddenly our payment page handler, deployed on Lambda, started throwing errors faster than we could reload the logs. Customers were reporting failed payments. Alerts were going off like firecrackers. We were scrambling.
Our first assumption? Some bug in our code. But the deeper we dug, the stranger things got. The code hadn’t changed. The behavior was erratic. Logs weren’t showing up in time. Functions were timing out before even getting to our business logic.
It took us an hour to realize what was really happening: we’d hit our Lambda concurrency cap—the default hard AWS limit of 1000 concurrent executions per region. A spike in usage had overwhelmed our functions, and requests were being throttled silently.
That day, we learned a powerful lesson: serverless isn’t magic—it’s just someone else’s server. And just because you don’t manage the infrastructure doesn’t mean you’re off the hook for everything else.
In fact, the exact opposite is true.
Building production-grade serverless systems requires deliberate engineering. You have to understand how cold starts impact latency, how concurrency limits throttle throughput, how observability is ten times harder when you don’t have persistent hosts, and how secret management can’t be an afterthought.
What started as an adventure in simplicity slowly evolved into a journey of deeper technical understanding—because while serverless lowers the barrier to entry, it raises the bar for architectural thinking.
In this post, I want to take you through our real-world journey—from our first Lambda function to the complex production systems we run today. You’ll see where serverless delivered, where it tripped us up, and how we learned to work with its strengths and around its limitations.
This isn’t a story of silver bullets or horror stories. It’s a grounded look at what it really takes to build resilient, scalable, and secure systems in a serverless world.
If you’re using Lambda or thinking about going serverless, I hope these lessons help you skip a few of the 2PM or 2AM crises we had to live through.
Let’s begin.
Let’s zoom into one of the biggest technical challenges we faced in the serverless world: concurrency limits—and how they can bring your system to its knees even when your code is perfect.
Concurrency Limits
If you ask most developers what they worry about in serverless, the answer you’ll often get is: cold starts. And yes, cold starts matter. They affect latency, especially in synchronous flows like API calls. But in our experience at Jodo, cold starts weren’t the show-stopper.
The real culprit? Concurrency limits. Let me walk you through what happened.
The Seminar That Broke Our System
We had recently launched a payment page feature. It was a simple HTTP API Gateway triggering a Lambda for our payment page. Clean, serverless architecture.
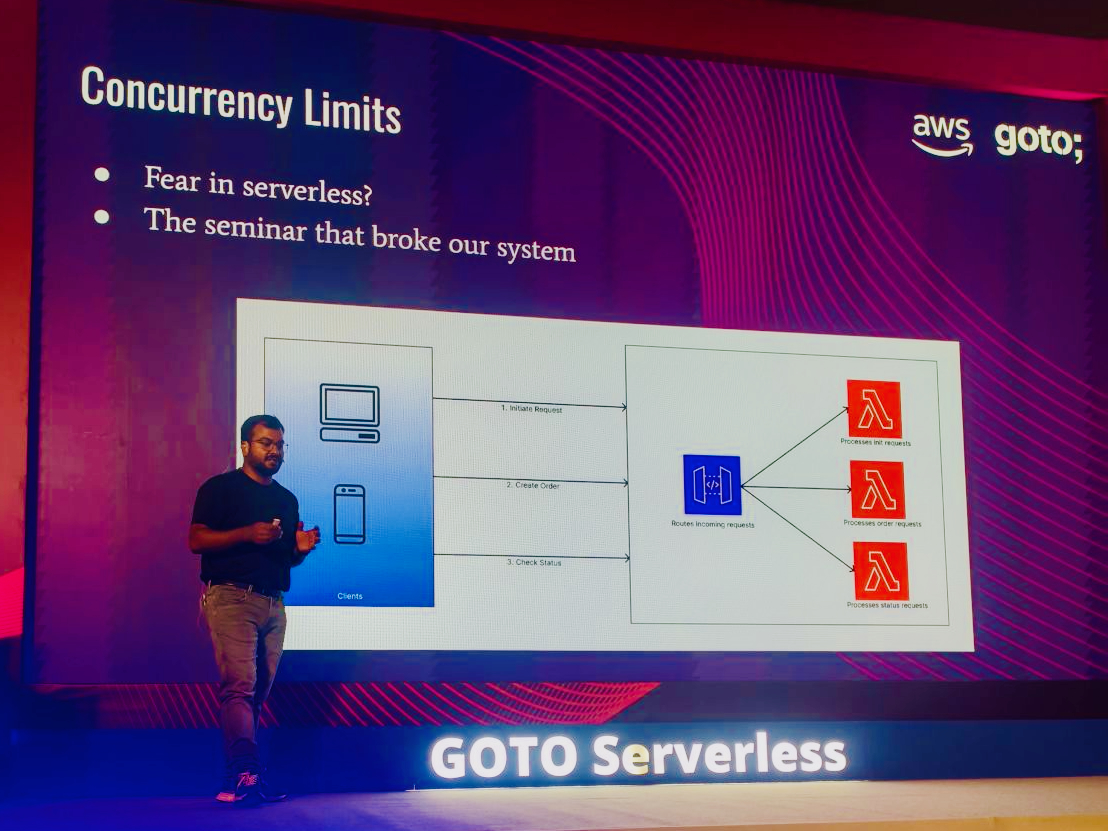
Then came a parent seminar at one of our partner institutions. After a quick counseling session, the host encouraged hundreds of parents to open the payment page from the QR… all pointing to that payment page. At the same time.
Here, if you notice - every page load triggered three steps.
- An initial request for pre-condition checks,
- A call to start the payment, and
- A final status check once the payment completed.
Each of those steps ran on a different Lambda function. So for every parent scanning the code, we were handling three separate invocations. Multiply that by a thousand — that’s over 3,000 concurrent requests in a flash.
Within minutes, traffic surged. And our system stalled. Users started getting errors. Our logs showed throttling. Why? We had slammed into the account-level concurrency cap.
Our Lambda was failing silently. Users were getting 5XX errors. Logs were showing throttling, but nothing obvious in the code. What was going on?
Turns out, we exceeded the default AWS limit of 1000 concurrent Lambda executions across our account—causing silent throttling.
By default, AWS gives every account a limit of 1000 concurrent executions per region. That’s shared across all Lambda functions. Not per-function—per-account.
We weren’t prepared.
Understanding Concurrency in AWS Lambda
Here’s how concurrency actually works:
- Every time a Lambda is invoked, AWS tries to spin up a new environment (or reuse a warm one) to handle that request.
- If too many invocations come all at once, and if the account-level concurrency limit is hit, AWS throttles the rest. This is across your account.
- You can define reserved concurrency for specific functions to guarantee execution—but that takes away from the shared pool.
- Available concurrency for unreserved functions is equal to your account concurrency limit minus the total reserved concurrency allocated across all Lambda functions.

For example, if your account has 1000 default concurrency limit and say 100 is reserved across few Lambda functions, then you’re only left with remaining 900.
This means your function could be fast, your code could be perfect, but if another function is chewing up concurrency (e.g., a spike in file uploads or batch jobs), everything else starts failing.
Provisioned Concurrency
We also looked into provisioned concurrency—a feature that pre-warms Lambda instances to eliminate cold starts and guarantees concurrency.
It works well for predictable, latency-sensitive functions (like synchronous APIs), but it’s not cheap:
- You pay for provisioned concurrency by the hour, whether it’s used or not.
- You still need to manage scaling manually (e.g., increase provisioned units before spikes).
We ended up using it selectively, for functions like payment page handlers that had clear peak times.
Concurrency Planning Is Architecture, Not Ops
A huge mindset shift for us was realizing that concurrency planning isn’t an operational concern—it’s an architectural one. We began treating concurrency like a first-class design dimension, just like latency or throughput:
- Can this function spike?
- Will it affect others if it does?
- Does it need its own quota?
- Would async execution help?
Concurrency — Lessons We Learned
With those realities in mind, here are some key lessons we learned—often the hard way.
- Concurrency limits are a platform-level bottleneck. You can’t ignore them just because Lambda “scales automatically.”
- Don’t assume bursts are rare. In our case, even a single webinar with a few hundred participants caused system-wide issues.
- Throttle-friendly design matters. Build mechanisms to catch and retry throttled requests.
- Monitor throttle metrics. Use CloudWatch alarms to proactively alert you before users notice.
- Use reserved concurrency wisely. Reserve capacity for critical functions to isolate them from others.
- Know when to use provisioned concurrency - but understand the trade-offs (performance vs cost vs complexity).
We’ll explore in the next section, not all invocations are created equal. One of the biggest shifts in our understanding was realizing the huge difference between synchronous and asynchronous Lambda flows—and how they stress your system in completely different ways.
When Serverless Didn’t Fit
After the concurrency incident, we got little smarter. We started planning for spikes, tuning concurrency settings, and isolating critical functions. But just when we thought we’d nailed the serverless game, another challenge came up—one that serverless simply couldn’t solve well. This time, it wasn’t about scaling fast, but about reliability and consistency over time.
Webhook Platform
As part of a new offering, we began integrating with ERP systems used by educational institutions. These systems needed to receive webhook events whenever a payment or fee-related event occurred in Jodo. Our first instinct? Serverless, of course.
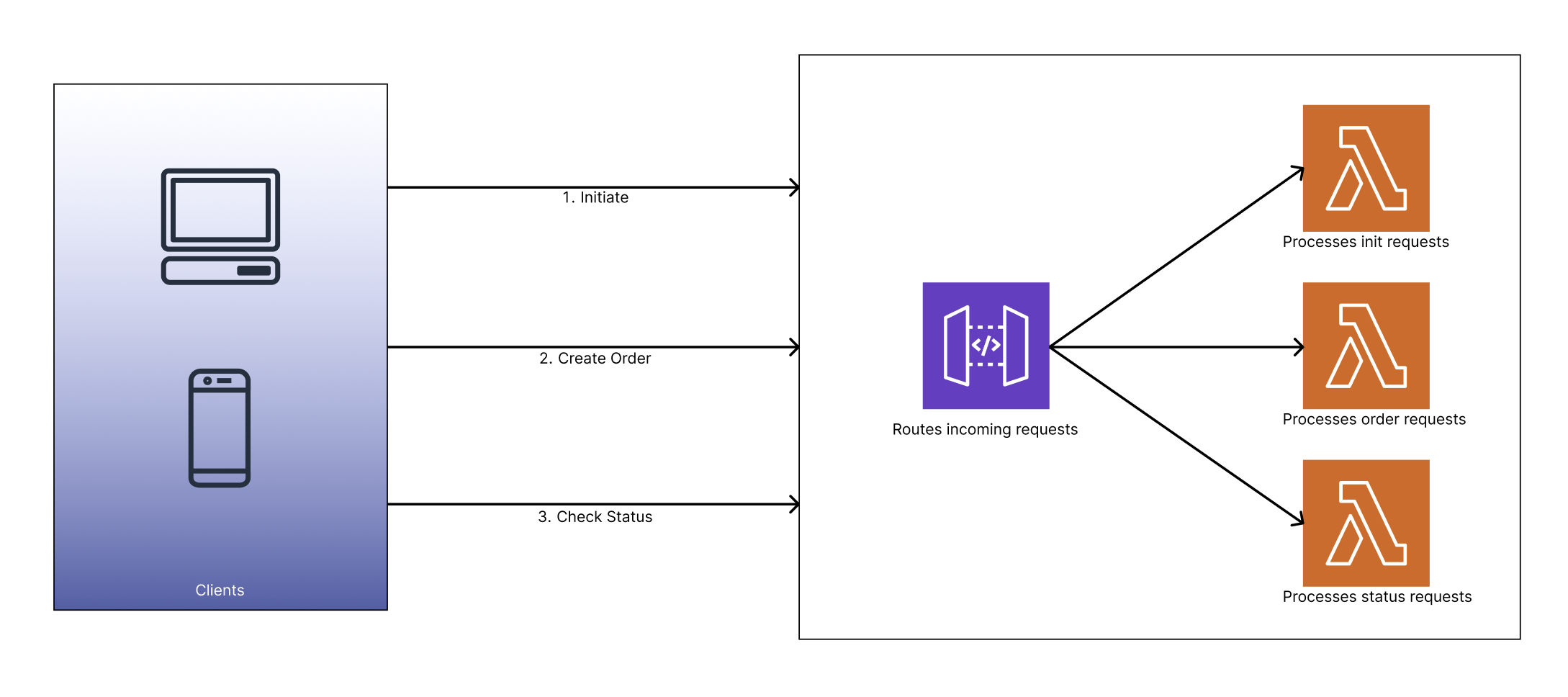
We built a set of Lambda workers. We designed priority topics for critical events and batch processing for low-priority ones. Messages flowed through Kafka. Lambdas picked them up. Events were dispatched to ERP systems.
As you can see in this diagram, we had bunch of services publishing the events to Kafka topic, which was getting processed by Lambda functions.
Everything was beautifully asynchronous. But then… we started getting timeout errors. Some webhooks didn’t go through. Others were being retried even though they had succeeded. Why?
The core issue was that Lambda was not designed for always-on, long-tail workloads:
- Some ERP servers were fast. Others were slow.
- Lambda’s 15-minute max execution time wasn’t enough for some edge cases.
- We had no guarantee of real-time reliability.
- If the function was cut mid-way, we couldn’t always store acknowledgments.
- Our clients were expected to implement idempotent receivers, but retries still made the flow noisy and error-prone.
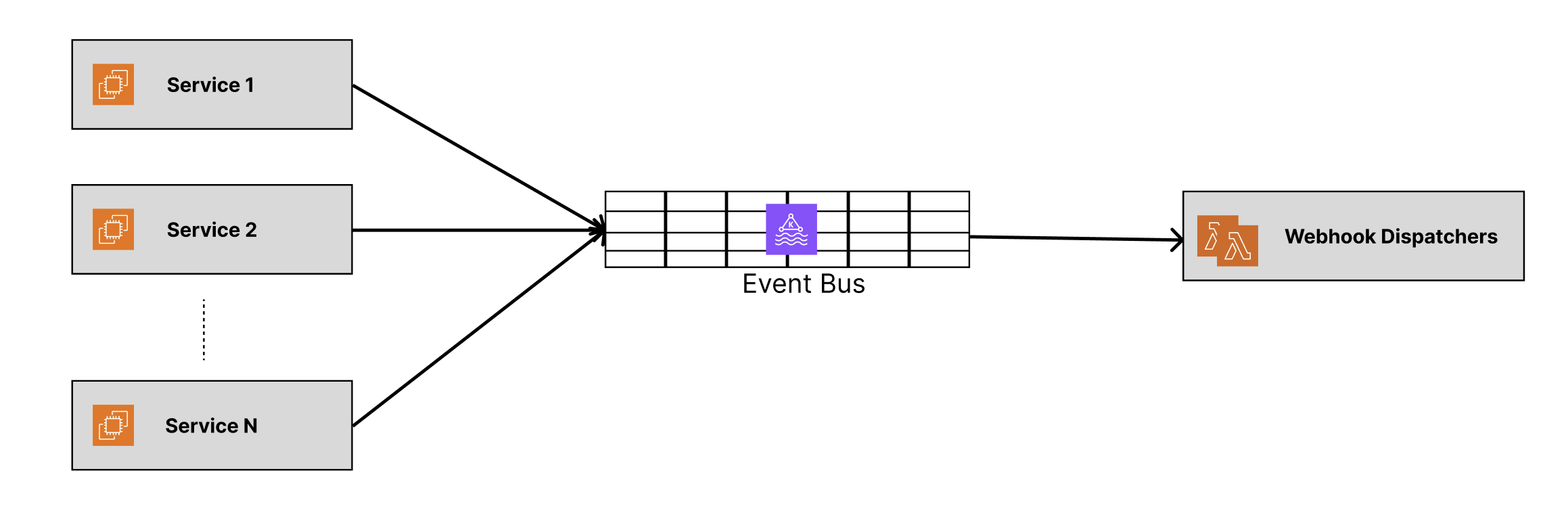
In above timeline, imagine a single Lambda function execution processing multiple events in a batch. For simplicity, let’s assume the events are processed sequentially. It’s possible that during processing, the Lambda function could reach the end of its lifecycle. Even if you add buffer time, delays can still occur.
As you can see, by the time we reach the last request in red r7, the Lambda function is at its maximum execution time. Even if the request successfully reaches the ERP system, we have no control over whether the acknowledgement can be stored, because the Lambda will terminate.
While ERP’s webhook handlers are expected to be idempotent, we wanted to avoid overloading them with unnecessary duplicate requests.
We realized this wasn’t a bursty workload. It was persistent, external-facing, and mission-critical. We needed something with:
- Long uptime
- Stable retry logic
- Control over connection reuse and backoff strategies
- Reliable state and logging—even in failure scenarios
That’s when we made the call: migrate this workflow out of Lambda.
Moving to EC2 and Containers
We replaced the Lambda workers with a container-based microservice running on EC2, orchestrated via auto-scaling groups and managed queues. This allowed us to:
- Control request pacing and retries at the network layer
- Use persistent HTTP clients with connection pooling
- Implement backpressure strategies
- Track acknowledgments even for long, complex interactions
Sure, we lost the auto-scaling magic. But we gained reliability, transparency, and confidence—especially when we had to meet SLAs.
Key Takeaways
- Serverless isn’t always the right answer.
It’s fantastic for elastic, short-lived, event-driven tasks—but it struggles with continuous, stateful, or sensitive integrations. - Don’t force-fit a workload.
If the shape of the problem doesn’t match Lambda’s constraints (e.g., time limits, cold starts, network variability), consider other options. - Reliability sometimes needs control.
And with serverless, the control surface is limited by design.
We still love Lambda. We use it for plenty of things. But this experience taught us something essential:
Just because you can use Lambda doesn’t mean you should.
In the next section, we’ll dive into a subtle, but critical topic: how sync vs async invocations behave differently in Lambda—and why understanding that difference saved us from more production surprises.
Sync vs Async Invocations
One of the most eye-opening discoveries in our serverless journey was that synchronous and asynchronous Lambda invocations behave very differently—and they fail differently too. At first glance, invocation mode doesn’t seem like a big deal. A function gets triggered, it runs, it responds. Right? Not quite.
Let’s break it down.
The Payment Page Spike Revisited
We mentioned earlier how a seminar full of parents opening payment page simultaneously brought our system to its knees.
That happened because the function was invoked synchronously—via API Gateway. Every click immediately triggered a Lambda. No queuing, no buffering. Just a flood of requests hitting our concurrency limit in real time.
It was like a traffic jam hitting a narrow bridge. No room to breathe. No delay mechanism. If Lambda couldn’t spin up fast enough, requests just failed.
In Contrast: Audit Logs via Async
Now compare that to how we handle audit trail logging.
These logs are generated from multiple services, but they’re not critical in real-time. So we push events into EventBridge, which triggers a Lambda asynchronously.
Here’s the key difference: in async mode, Lambda uses an internal event queue (with built-in retries and DLQ support) to buffer incoming requests. If concurrency is maxed out, Lambda doesn’t immediately fail. It waits. It drains the queue as capacity becomes available.
The result? More resilience under sudden load.
But this comes with its own risks. The queue has limits. The retries can flood downstream systems. If something fails silently (like downstream timeout), retries could trigger further chaos unless handled properly.
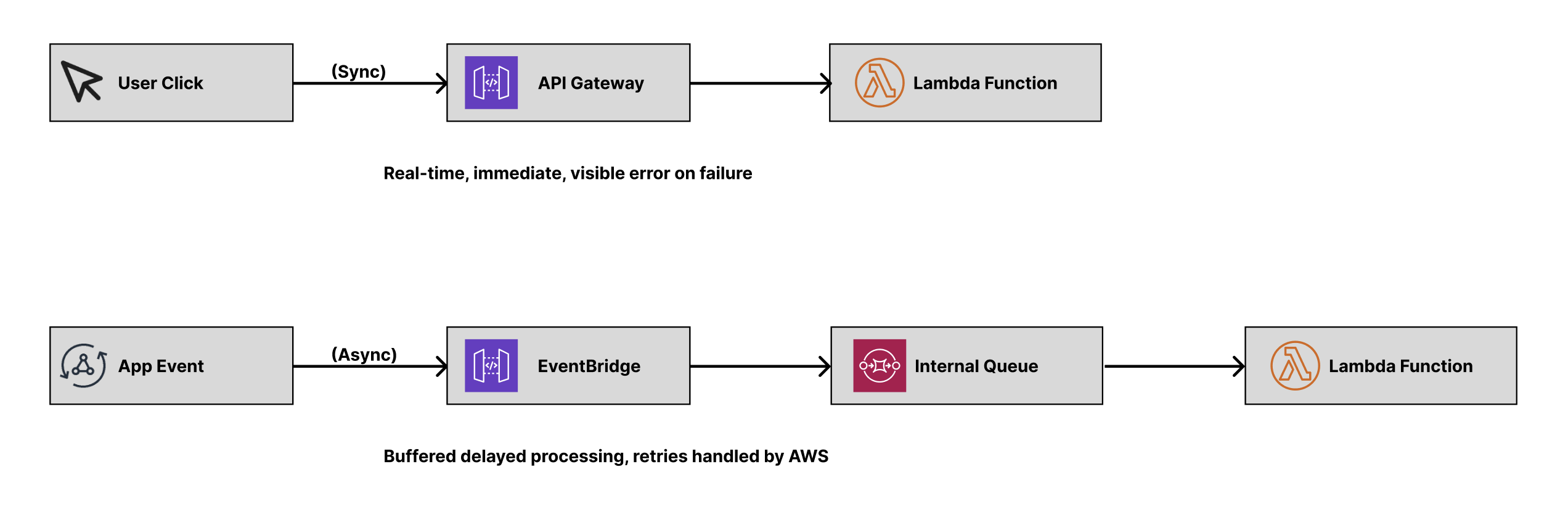
Here is what really happens under the hood.
| Aspect | Synchronous Invocation | Asynchronous Invocation |
|---|---|---|
| Triggered by | API Gateway, SDK call, ALB | EventBridge, S3, SNS, direct async invoke |
| Client behavior | Waits for function to finish | Fire-and-forget |
| Retry responsibility | Caller must retry on failure | AWS retries up to 2 more times before DLQ (if configured) |
| Concurrency impact | Each call immediately consumes concurrency | Requests queued if limit is hit |
| Failure visibility | Immediate to caller | May fail silently unless monitored |
| Risk | Throttling = instant user-facing error | Retry storms, delayed processing, potential overload on downstream APIs |
Things the Docs Won’t Tell You
Here’s what you won’t read in the docs, but absolutely need to know.
- Sync traffic is high-risk - you only get one shot. Any delay, throttle, or cold start shows up instantly to the end user.
- Async helps absorb spikes - but you must monitor queue depth, latency, and failure rates, or you’ll be flying blind.
- Different invocation types require different architecture. Sync flows need provisioned concurrency and low latency paths, whereas async flows need backpressure handling, DLQs, and idempotent processing.
- Design your error handling upfront. With async, AWS retries automatically—but that can be dangerous without safeguards like:
- Dead-letter queues
- Retry limits
- Alerting on failure patterns
Understanding the nuances between sync and async invocations completely changed how we design flows. Now, when we build new systems, one of the first questions we ask is:
Does this need to be real-time? Or can it tolerate delay?
Because the answer determines not just performance—but reliability, scalability, and cost.
Next, we’ll explore another critical area where serverless adds both value and hidden risk: security—and how we learned (the hard way) to manage secrets the right way.
Secrets and Security in Serverless
One of the most dangerous assumptions you can make with serverless is this:
Myth: AWS is secure by default, so I don’t need to worry about security.
Yes, AWS provides strong foundational security—but using it correctly is your responsibility.
In our early days with Lambda, we made a classic mistake was that we stored database credentials and API keys as environment variables in our functions. It was quick. It was easy. It was also not secure enough.
Environment Variables and Secrets
Environment variables seem convenient for storing secrets. You define them during deployment, and they’re available in your handler code. But this approach comes with serious limitations that we learned about the hard way. They’re static, meaning any rotation or change requires re-deploying the function, creating operational overhead and potential downtime windows. They’re visible to anyone with access to Lambda configuration, even those with read-only roles, expanding your security surface unnecessarily. Perhaps most dangerously, they’re often logged accidentally during debugging sessions, and they cannot be dynamically fetched or audited in real time, making compliance and security monitoring nearly impossible.
We realized this wasn’t sustainable—especially as our system started interacting with payment gateways, CRM systems, and customer PII.
We migrated our sensitive credentials to AWS Secrets Manager, and that changed everything. Secrets were stored securely, encrypted at rest with IAM access policies. We could rotate them automatically using built-in rotation functions. Our Lambdas could fetch secrets at runtime, removing the need for static config. We gained auditability, versioning, and better control.
Best Practices We Adopted
We learned to fetch secrets outside the handler function, placing the secret fetch in the global scope of the Lambda so it happens only once during a cold start, with subsequent warm invocations reusing the cached secret. This pattern dramatically improves performance while maintaining security. We became religious about avoiding logging secrets, even during development—it seems obvious, but you’d be surprised how easy it is to accidentally print a secret during testing and forget about it in production code. For high-frequency access patterns, we implemented in-memory caching to reduce latency and minimize Secrets Manager costs, which are charged per API call. We set fine-grained IAM policies that grant Lambda access only to the specific secrets it needs, avoiding wildcard policies that create unnecessary security exposure.
Finally, we enabled automatic rotation for AWS-supported secrets like RDS credentials and API keys, achieving zero-downtime rotation that limits long-term exposure risk.
Secrets Manager isn’t free—$0.40 per secret per month plus $0.05 per 10,000 API calls. For a system with dozens of secrets and high-frequency access, this can add up. We learned to batch secret retrievals where possible and cache aggressively. The cost is worth it for the security benefits, but it’s something to factor into your architecture decisions early.
A Note on IAM: Fine-Grained is Better
IAM can feel painful, especially when starting with serverless, and the temptation is strong to assign a wide role like AWSLambdaFullAccess just to “get things working.” But over time, this creates a massive security surface that becomes harder and harder to audit and control. Instead, we learned to use least privilege principles, creating scoped roles with GetSecretValue permissions only on required secrets. We segment functions so that no single Lambda has access to everything, and we audit regularly using tools like AWS IAM Access Analyzer to review what permissions are actually being used versus what’s been granted.
Security Is Part of Architecture
We used to treat security as an “ops” concern. But in the serverless world—where functions are short-lived, access is granular, and everything is remote—security is part of architecture. It touches how we write code, structure permissions, manage secrets, and even choose which AWS services to use. And the lesson we keep coming back to?
Secure-by-default is a myth. Secure-by-design is the goal.
In the next section, we’ll turn to something just as critical as security—observability. Because even the most secure function won’t help if it fails silently at 2AM and you can’t see why.
Observability: Your 2AM Lifeline
If there’s one lesson we learned the hard way in our serverless journey, it’s this:
Without observability, you’re flying blind.
At 2AM, when your Lambda function starts failing silently or your async queue stops draining, it doesn’t matter how elegant your architecture is—if you can’t see it, you can’t fix it.
And with serverless, observability is both more important and more challenging than in traditional systems.
Why Observability is Harder in Serverless
In a traditional environment, you can SSH into a machine, tail logs, check CPU/memory stats, and piece things together. With serverless, that luxury disappears entirely. There’s no persistent host to inspect, functions are ephemeral—they spin up, run, and die without a trace. Logs arrive delayed and sometimes out of order, making it nearly impossible to reconstruct what actually happened during a failure. Every function becomes a black box unless you explicitly design it to report what’s going on inside.
The Metrics That Matter
We quickly learned which metrics are worth watching and built dashboards and alerts around them. Init duration tells you how long AWS takes to spin up your Lambda—high init durations signal cold starts that create latency spikes, especially problematic for synchronous APIs. Throttles became our most important signal for concurrency issues, because even a few throttles can mean missed user actions, so we alert on any sustained increase.
Memory allocation versus actual usage helps optimize both performance and cost—under-allocating leads to slower functions and longer billed time, while over-allocating burns money unnecessarily. Billed duration helps detect inefficient handlers, and if duration increases over time, it’s usually a sign to check dependencies and payload sizes. For async flows, monitoring errors and retries becomes critical to spot retry storms, dead letter queue backlogs, or stuck queues before they cascade into bigger problems.
Logging: Go Beyond logger.info
Structured logging became our lifeline—JSON-formatted entries with consistent keys that let us correlate requests across functions. We include essential metadata like requestId, userId when applicable, functionName, invocationType, timestamps, and event source information in every log entry. Then we centralize and search through CloudWatch Logs Insights, Elasticsearch or OpenSearch, or third-party tools like Coralogix. This structured approach makes it possible to trace a request end-to-end, even across async boundaries where traditional debugging falls apart.
Tracing: Connect the Dots
For distributed tracing, AWS X-Ray proves helpful, especially with Lambda, API Gateway, or SQS chains, letting you visualize function invocations and durations, trace downstream calls to DynamoDB or external APIs, and spot latency bottlenecks. However, X-Ray requires careful instrumentation, adds some latency overhead, and doesn’t automatically cover third-party SDKs or custom layers, so you need to weigh the observability benefits against the performance cost.
A Robust Observability Stack (Minimal Setup)
| Component | Tooling |
|---|---|
| Logs | CloudWatch Logs + JSON structure |
| Metrics | CloudWatch Metrics + Alarms |
| Tracing | AWS X-Ray (or OpenTelemetry) |
| Dashboards | CloudWatch Dashboards or Datadog |
| Alerts | SNS, PagerDuty, or Slack integrations |
| DLQ Monitoring | SQS metrics + EventBridge alerting |
With strong observability in place, we transformed our operational capabilities. We can now catch throttle issues before users report them, see exactly when cold starts spike and correlate them with traffic patterns, trace slow requests to specific dependencies, and alert on function errors before retries snowball into system-wide failures. Most importantly, we can debug issues faster at 2AM with significantly less stress and guesswork.
Observability = Survivability
In serverless, things can fail silently. Functions can be retried endlessly. Downstream services can be overwhelmed by async queues. So if you take away one thing from this section, let it be this:
You can’t operate what you can’t see.
Observability isn’t optional—it’s your primary defense against unknown unknowns.
Consider the payment page handler incident I mentioned earlier. Without proper observability, we spent an hour chasing ghosts—checking code, redeploying, scratching our heads. With the right metrics in place, we would have seen the throttle alerts immediately and known exactly what was happening. The difference between one hour of downtime and five minutes of targeted response.
Setting Up Alerts That Actually Help
Not all alerts are created equal. We learned to alert on trends, not just thresholds. A single throttle might be noise, but throttles increasing over a 5-minute window signals trouble. Cold start spikes during business hours matter more than overnight blips. Error rates above 1% for payment flows require immediate attention, while 5% errors on non-critical background jobs can wait until morning.
Observability Costs: Plan Ahead
CloudWatch Logs can become expensive at scale—we learned to be selective about what we log and how long we retain it. Structured logging helps because you can filter and sample more effectively. X-Ray tracing costs add up with high-volume functions, so consider sampling rates that give you visibility without breaking the budget.
In the next section, we’ll explore how we structured our infrastructure at Jodo to balance serverless benefits with traditional control—and why we moved to a hybrid approach.
Why We Chose Hybrid
As we scaled Jodo’s systems, we realized something important: no one architecture fits all workloads.
When we started, we leaned hard into serverless. And it worked great—for a while.
We used AWS Lambda to process incoming webhook events, generate payment links, manage audit logs, and run utility functions like URL shorteners. With tools like API Gateway, SQS, EventBridge, and S3, our team was moving fast. Deployment pipelines were lean. Costs were low. There were no servers to patch, and scaling felt automatic.
But then reality hit.
We started encountering use cases that didn’t fit neatly into the serverless model:
- Services that required long-lived processing (longer than Lambda’s 15-minutes max).
- Integrations that demanded custom binaries or system-level dependencies.
- Features where we needed stable outbound connections.
- Workloads with 24x7 traffic that weren’t cost-effective on a per-invocation billing model.
- Systems where we had to maintain state across operations—which serverless explicitly avoids.
Rather than fight Lambda’s constraints, we decided to build around them.
That’s when our hybrid infrastructure strategy took shape.
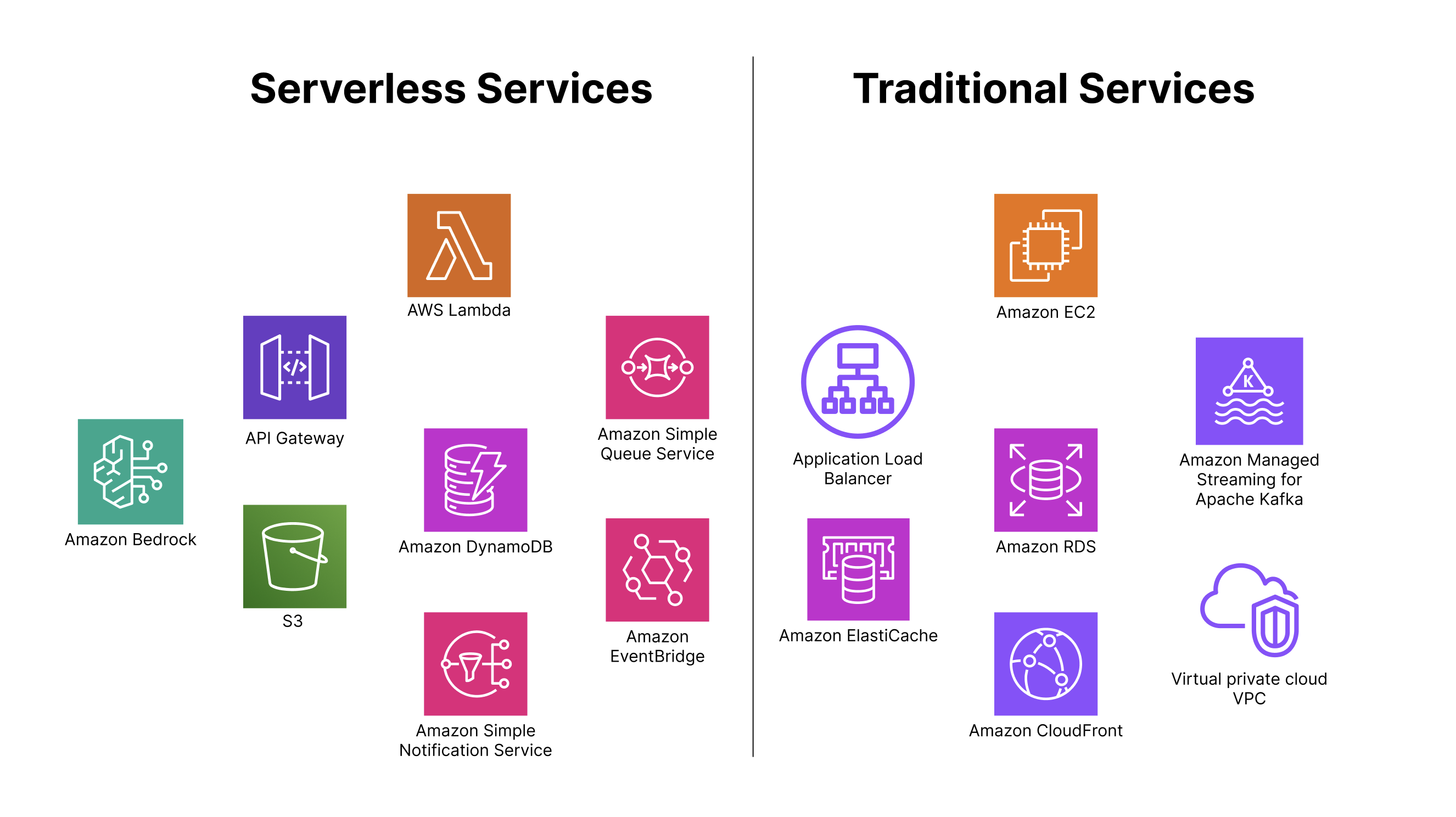
Today, our architecture is a carefully considered hybrid of serverless services and traditional compute. We use AWS Lambda, API Gateway, SQS, S3, and EventBridge for handling bursty, asynchronous workloads—ideal for scenarios with unpredictable spikes, such as generating payment links after bulk reminders. These serverless tools help us move fast, scale automatically, and keep infrastructure overhead low. In contrast, we reserve EC2 instances, load balancers, and Docker containers for services that are steady, stateful, or long-running. This gives us full control over performance tuning, networking, and system-level dependencies—especially critical for ERP integrations and background processing. We also integrate AWS Bedrock into our stack for AI-powered workflows like code reviews and ticket triage, where we orchestrate inference through Lambda but rely on Bedrock’s managed foundation models. This hybrid model gives us the best of both worlds: the agility of serverless for spiky workloads, and the predictability and control of traditional infrastructure where it matters most.
Why the Hybrid Model Works
- Flexibility: We can match the right tool to the right job. Need autoscaling and pay-per-use? Use Lambda. Need custom runtime or control over networking? Spin up a container.
- Cost control: Not all workloads benefit from serverless pricing. Long-running services on EC2 often cost less over time.
- Reliability: For always-on systems, traditional infra avoids cold starts and concurrency caps.
- Scalability: Serverless shines for sudden surges. Traditional infra offers predictable performance for critical, always-on components.
Here’s how we think about the split:
| Workload Type | Where We Run It | Why |
|---|---|---|
| Webhook processing | Lambda | Spiky demand, async, short-lived |
| Payment link generation | Lambda + API Gateway | Bursty, event-driven |
| ERP integrations | EC2 + Docker | Needs reliability, runs 24x7 |
| Audit trail logging | Lambda → S3 | Fire-and-forget events |
| Backend APIs & dashboards | EC2 + Load Balancer | Stateful sessions, fine-grained control |
Architecture is a journey, not a destination.
If there’s one thing we’ve learned, it’s that infrastructure evolves with your product. What works at MVP may not work at scale. What looks simple today might create hidden costs tomorrow.
Serverless wasn’t a mistake. It gave us speed, iteration, and scalability at a time when we needed it most.
But we’ve also come to appreciate the power of traditional infrastructure—especially when uptime, latency, and control are non-negotiable. That’s why we don’t treat serverless vs containers as a binary choice. For us, it’s a spectrum—and the right architecture depends on the shape of the workload.
The Myth of Simplicity
This brings me to the biggest myth of serverless: its “simplicity.”
One of the most compelling promises of serverless is its simplicity. No servers to manage. No scaling logic to write. No infrastructure to babysit. You just write the function and move on.
But here’s the catch: simplicity on the surface often hides real complexity underneath.
When we first adopted Lambda, we thought we were offloading responsibilities. In reality, we were just shifting them to a different layer of the stack, often one that was harder to see, debug, and control.
Let’s break this down:
| Perceived Simplicity | Actual Complexity |
|---|---|
| No servers to manage | Platform quotas, concurrency limits, cold starts |
| Auto-scaling “just works” | Planning for concurrency, throttling under load |
| Easy to deploy | Hard to debug across stateless, ephemeral executions |
| Pay-per-use = low cost | Spiky usage can lead to unpredictable bills |
| Secure by design | Fine-grained IAM, secret management, cross-service access |
Take auto-scaling, for instance. It sounds like a dream. But we learned that auto-scaling is only as good as your account’s concurrency limits. Once we hit those—especially during customer spikes like webinar promotions or fee reminders—we weren’t scaling up. We were getting throttled.
And let’s not forget debugging. With traditional services, if something breaks, you SSH into a machine, poke around, tail some logs, and find the problem. With serverless? Your function could be cold-starting, timing out, failing silently, or retrying asynchronously—all while your logs arrive late or out of order.
You have fewer knobs to turn and fewer signals to observe—unless you build them yourself.
The same goes for security. While serverless platforms like AWS Lambda are secure by default, they’re not secure by accident. We had to deal with IAM permissions that were too broad or too narrow, environment variables leaking secrets, and third-party SDKs behaving unpredictably in restricted runtimes.
So yes—serverless does remove the burden of infrastructure management.
But that doesn’t mean you can skip architecture.
You still need to think about failure modes, latency budgets, scaling behaviors, and cost controls. You still need to build observability and resilience into every flow. And you absolutely need to know the constraints and quirks of the platform.
Serverless can be simple—but only after you’ve engineered for its complexity.
That’s the paradox.
Lesson Learned
By this point, you’ve seen our story unfold—from the 2PM payment handler meltdown to concurrency battles, architectural pivots, and the pursuit of observability. We didn’t arrive at best practices overnight. Each production fire, missed alert, or scaling failure taught us something the hard way.
Here’s a distilled list of the most valuable lessons we learned along the way—lessons we now treat as architectural guardrails for any serverless project.
Platform Limits > Code Quality
You can write the cleanest, most efficient, and thoroughly tested Lambda function—but it won’t matter if you hit a concurrency cap, your async queue overflows, or you exceed a payload size limit. Even a cold start that adds just two seconds of latency can be enough to break a real-time user experience. In the world of serverless, code quality alone isn’t enough. You need a deep understanding of the platform’s constraints—because success isn’t just about how your function runs, but whether the infrastructure allows it to run at all.
Cold Starts Are Not the Only Problem
Yes, cold starts can cause latency spikes. But we learned that concurrency throttling, misconfigured async retries, and memory-starved functions caused way more production issues. Know what you’re optimizing for:
- Cold starts? → Use provisioned concurrency.
- Throttling? → Reserve concurrency or switch to async.
- Long queues? → Monitor backpressure and DLQs.
Serverless Demands Thoughtful Design
Don’t assume you can “just throw a Lambda at it.” Ask these questions.
- Does this function need to run under 15 minutes?
- Is this flow synchronous or async?
- Will this need fine-grained networking or VPC access?
- What happens if it retries multiple times?
Serverless doesn’t remove architectural decisions—it amplifies them.
Early Decisions Have Long Tails
One example: we initially chose HTTP API Gateway because it was cheaper and faster to set up. But later, we needed built-in throttling and request validation—which REST API Gateway supports out of the box. We had to re-architect mid-flight. Lesson?
Don’t optimize for cost alone. Optimize for future flexibility.
Choose the Right Tool for the Job
Choosing the right tool for the job is crucial. AWS Lambda is well-suited for event-driven, bursty, and short-lived tasks where automatic scaling and simplicity are key. But for long-running, stateful, or more complex workloads, containers or EC2 often provide the control and reliability you need. In many cases, the best approach isn’t picking one over the other—it’s blending both. Hybrid architectures let you optimize for flexibility, performance, and cost. Every workload has a shape, and your infrastructure should be shaped to match it—not forced into a one-size-fits-all solution.
Observability Isn’t Optional
No logs? No alerts? No tracing?
You’ll regret it—at 2AM.
Instrument your functions from day one. Add structured logs. Set alarms. Connect traces. Visibility isn’t a bonus feature—it’s your lifeline.
Experiment, but Plan for Growth
Serverless lets you build fast—but if your product succeeds, that prototype becomes production.
So:
- Add DLQs even if you think “we’ll never need retries.”
- Use correlation IDs even if the flow is simple.
- Separate permission scopes, even for internal tools.
Build like you’ll have to debug it six months from now.
Pre-Deployment Checklist
Before shipping anything serverless to prod, we now ask:
- Have you estimated concurrency needs?
- Is the invocation sync or async?
- Are all secrets managed securely (not in env vars)?
- Do you have alerts on errors, throttles, and retries?
- Will this function ever run longer than 15 minutes?
- Are you protected with DLQs, timeouts, and retry limits?
Serverless isn’t just an infrastructure model—it’s a mindset. It asks you to think differently about design, reliability, and scale.
And in the next section, we’ll push that thinking even further—with a challenge that forces you to design both inside and outside the serverless paradigm.
Challenge Your Assumptions
By now, it’s clear that serverless can be powerful—but it also comes with a unique set of trade-offs. One of the best ways to internalize those trade-offs is through a mental exercise we started using at Jodo:
Design a system twice—once with serverless, once without. Then compare.
This simple exercise has reshaped how we approach architecture.
The Thought Experiment
Let’s say you’re building a file processing pipeline. Your serverless version might look like:
- S3 bucket triggers a Lambda
- Lambda parses metadata, saves it to DynamoDB
- Another Lambda triggered via EventBridge does further processing
Now, redesign that same system using containers or EC2:
- Files are uploaded to an NGINX load-balanced endpoint
- A worker service (in Docker) picks up files from a directory
- A background daemon processes and persists data to PostgreSQL
Now ask yourself:
- Which version handles bursty traffic better?
- Which one gives you more control over retry logic or parallelism?
- Where’s your observability better?
- What’s the total cost at small scale vs large?
- How does multi-tenancy change the design?
Introduce Real-World Complexity
Next, make the problem harder—like it would be in real life. Add:
- Multi-tenancy: Different customers with different throughput and SLA needs.
- PII handling: How do you manage security, compliance, and logging?
- Cost constraints: What happens when usage doubles?
- SLA targets: Does the architecture still hold up under pressure?
This helps you uncover blind spots early.
For example:
- In a multi-tenant system, shared concurrency pools can create noisy neighbor problems in Lambda.
- Cost-based triggers like “Lambda duration × invocations” can explode under misuse.
- You may need dedicated isolation per tenant—serverless can’t always offer that cleanly.
What Stays the Same? What Changes?
This is the final part of the exercise: zoom out.
- The business logic likely stays the same.
- But deployment, scalability, isolation, and observability approaches shift dramatically.
- The “glue” between services might be different: in serverless, it’s often EventBridge or SQS; in traditional systems, it might be cron jobs or internal queues.
Ask yourself:
What’s truly core to your system, and what’s just an implementation detail?
The more systems you design this way, the better you get at making intentional, not accidental architectural choices.
The Bigger Lesson
This challenge isn’t about saying serverless is better or worse. It’s about understanding why you’re choosing it—and what you’re trading off in return.
If Lambda didn’t exist, what would you build? Would your system be more reliable? More flexible? Easier to debug? The best architects we’ve worked with can answer those questions confidently. Because they’re not just building for today’s use case—they’re building for tomorrow’s scale, constraints, and chaos.
In our final section, we’ll wrap up with key takeaways and how we’re continuing to evolve our use of serverless at Jodo—even beyond APIs and webhooks.
The Future – Going Beyond Lambdas
At Jodo, serverless was never just a trend—it was a strategic choice. It helped us move fast, iterate with confidence, and scale without hiring a massive ops team. But the real power of serverless comes when you go beyond the basics.
In recent months, we’ve been pushing the envelope on how we use serverless—not just for core product workflows, but also for internal automation, AI integrations, and developer productivity. One area where serverless has really shined for us is in orchestrating AI workflows. Take our code review process, for example: roughly 80% of our code reviews now run through a serverless pipeline that uses Claude Sonnet, orchestrated via AWS Lambda. The flow is elegant in its simplicity—developers submit PRs, metadata gets parsed, review context is sent to Claude, and feedback is generated and posted back into our tools. It’s fast, scalable, and fully async. Similarly, we’ve automated our ticket triage system using Bedrock services triggered via EventBridge and handled by Lambda, where tasks like labeling, priority detection, and first-response suggestions run without human intervention.
These workloads share common characteristics that make them perfect for serverless: they happen on unpredictable schedules, need fast parallel execution, involve short-lived stateless processing, and must scale with our engineering team rather than requiring dedicated servers. We’re now experimenting with even more sophisticated patterns—event-driven multi-step workflows using Step Functions and Bedrock, on-demand container compute with AWS Fargate for mid-size ML tasks, and cross-tenant pipelines that isolate processing per customer using per-tenant queues and concurrency shaping.
As our use cases get more complex, we’re not moving away from serverless—we’re evolving how we use it. The more you use serverless, the more you realize that Lambda is just one piece of the puzzle. Serverless now spans compute through Lambda and Fargate, storage via S3 and DynamoDB, messaging with SQS, EventBridge, and SNS, AI and ML through Bedrock, SageMaker, and Claude, and automation using Step Functions and CloudWatch Events. This lets us stitch together powerful workflows without managing infrastructure—but still with intentional architecture. We no longer think of serverless as a shortcut. We treat it as a canvas—a composable set of primitives that let us build fast, build reliably, and build systems that scale without growing complexity. And the guiding principle remains the same:
Use the right tool for the job—but never stop asking what the job will look like tomorrow.
In the final section, we’ll wrap up with the most important takeaways from our journey—and what we hope you can apply to your own.
Final Takeaways
So here we are—at the end of a journey that started with a single Lambda function and evolved into a production-scale, hybrid system powering payments, audits, AI workflows, and more. What started as a way to move fast became an exercise in deep engineering discipline. And if there’s one message we want to leave you with, it’s this:
Serverless is not magic. It’s just someone else’s server.
But when used intentionally—with a clear understanding of its strengths, limitations, and quirks—it can be one of the most powerful tools in your architecture toolkit. Here is what really mattered in the end.
But when used intentionally—with a clear understanding of its strengths, limitations, and quirks—it can be one of the most powerful tools in your architecture toolkit. What really mattered in the end was learning that thoughtful design beats hype every time. Jumping into serverless without understanding the cost and concurrency model is a recipe for surprises, while designing around platform limits and usage patterns is what makes it scale. We discovered that observability isn’t overhead—it’s non-negotiable. Metrics, logs, traces, and alerts become your only line of defense when something goes wrong in production, especially when you can’t SSH into a server to debug.
Security, we learned, is architecture. Managing secrets, scoping IAM permissions, and rotating credentials aren’t ops chores—they’re architectural decisions that shape how safe and scalable your systems become. Perhaps most critically, concurrency management is everything. While cold starts might annoy users, throttling silently breaks entire systems, especially in high-traffic or synchronous flows. You need to plan for concurrency like you plan for storage or CPU—it’s that fundamental.
Finally, and this took us the longest to accept, not everything belongs in Lambda. If a workload is long-running, stateful, sensitive to retries, or tightly coupled with external systems, consider containers or EC2. The goal isn’t to use the trendiest abstraction—it’s to use the right one for the job at hand.
At Jodo, we’re still learning. Still iterating. Still finding new ways to blend serverless primitives with traditional systems to deliver performance, scale, and reliability. Whether it’s processing payments, running code reviews through AI, or building internal automation pipelines—serverless isn’t where we stopped. It’s where we started.
Thanks for reading.
We hope our experience helps you make better architectural choices, avoid the midnight surprises, and unlock the full potential of serverless—with your eyes wide open.
If you’ve made it this far, maybe take a moment and reflect:
What’s the Lambda in your life that’s doing more than it should?
And what would it look like if you rearchitected it—deliberately?




